Social media data is one of the recent and prominent sources of georefrenced social information. It allows in-situ insights into the everyday lifes of ordinary people. For all that, social media data also confronts us with considerable analytical challenges. One of these challenges is the mingling of different user habits, functions of geographic space and, more generally, semantic inaccuracies caused by the informal nature of the data. Taken together with an autonomous data collection procedure, the result is a mixed point pattern, subsuming different subpopulations in a spatially intermixed manner. In a recent study we investigated the topological consequences of some of these issues. We thereby focused on topological aspects and show how these affect spatial analysis outcomes. Our analysis is conducted at the level of spatial autocorrelation estimation. The latter is the underlying data characteristic which is driving patterning, and therefore the basis of a great deal of spatial methodology. Our focus thus guarantees a broad relevance of our results.
Data and Methods:
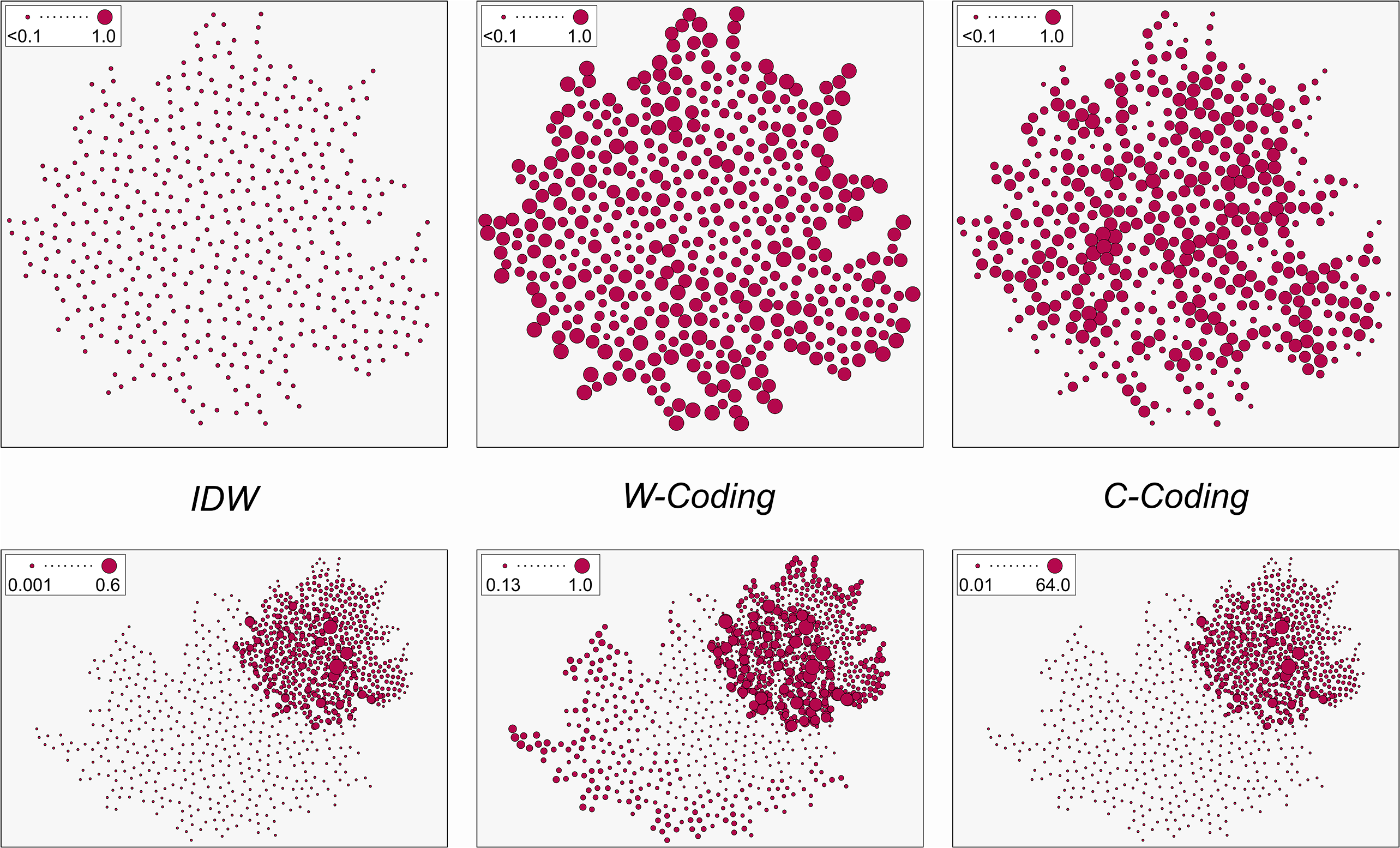
We first demonstrate how established spatial methodology responds to the characteristics of social media data. We therefore use a semantically perprocessed London-based Twitter dataset, which was crawled over a period of one year. This dataset is spatially analyzed by estimating an empirical semivariogram. To further allow disaggregated insight into covariation patterns, we additionally compiled a heatmap of the single estimated covariance terms, plotted against distance. For the rest of the paper a synthetic dataset is used. This allows investigations without external disturbances, and thus clearly pointing out the effects of interest. In a first step the eigenvalues of local spatial weight matrices are employed to analyse the topological influence of single points and whole regions onto the overall analysis. This step allows the identification of topological outliers. We also analyze the respective effect of these on the distribution of Moran’s I, a popular spatial autocorrelation estimator. Moran scatterplots are then used to highlight how topological outliers influence conclusions drawn from spatial analyses. Finally, serial autocorrelation measurements across scale differences are used to show interactions with scale.
Results:
The eigenvalue analysis of the spatial layout has shown that topological outliers emerge in regions where different point pattern populations mix up. Further, these outliers have the tendency to being much stronger than outliers at the boundaries of patterns or other more conventional outlier types. They thus massively control analysis results. The subsequent analysis of Moran scatterplots has shown that these outliers cause additional components that might either reinforce or contradict the actual spatial pattern of data. These components do reflect the spatial effects associated with the interaction between the overlapping patterns. We are therefore in fact investigating not just one but multiple spatial phenomena in a single analysis. Spatial effects might thus be under- or overestimated erroneously. The spatial scale of the mixed patterns thereby plays an important role. While the real pattern (i.e., the one an analyst is actually interested in) behaves tractable when scales become increasingly dissimilar, the disturbing components seem to become increasingly chaotic. This shows that the disturbing and misleading effects identified by the Moran scatterplots become even more problematic when the scales of the comingled patterns are very different.
Conclusions:
Our results show that most established spatial analysis methodology does not behave well with the autonomous and highly diverse character of social media data. Analyses should thus be undertaken with care and increased levels of type I and type II errors should be expected. The design of the pairwise spatial relationships (i.e., the spatial weights matrix, or any adjacency model) thereby deserves keen attention, because it massively controls the impact of topological outliers. The most important conclusion is to advice spatial researchers to take care in separating different phenomena from social media data previous to any actual analysis. This, however, is only possible to some degree (e.g., because spatial perception is an active field of research and accurate modeling still intractable). Thus, the highlighted issues persist and require rethinking spatial analysis methods.
Westerholt, R., Steiger, E., Resch, B. and Zipf, A. (2016): Abundant Topological Outliers in Social Media Data and Their Effect on Spatial Analysis. PLOS ONE, 11(9), e0162360. doi:10.1371/journal.pone.0162360.